Member-only story
Try Hugging Face’s Open Source Text-to-Video Model (modelscope-text-to-video-synthesis)

This Monday, Victor M twitted a video clip using Hugging Face’s open source Text-to-Video tool(released on the same day). Wow, I just tried it. It’s fun. Here are the related resources, including the links to the web app and the model.
- Introduction and demo
- Try it yourself
- Limitations

1. Introduction and demo
This model is built upon a multi-stage text-to-video generation diffusion model, which consists of three sub-networks: text feature extraction, text feature-to-video latent space diffusion model, and video latent space to video visual space. The model utilizes the Unet3D structure and generates videos through an iterative denoising process from the pure Gaussian noise video. (They didn’t list any related paper on the homepage, I don’t understand the words in bold)
Check some demos on their website:

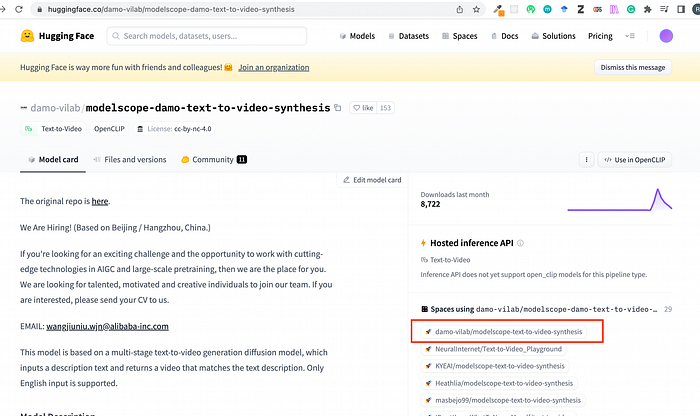
2. Try it yourself
(1) Web App
We can try the web app on the above ModelScope’s website or on Hugging Face.
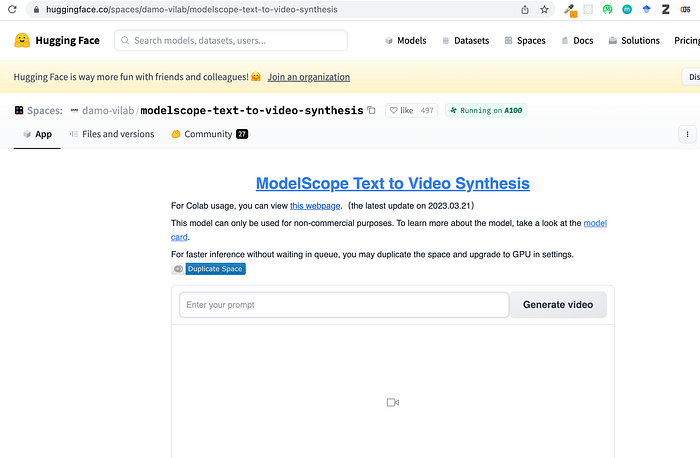
Let’s try the prompts from the demo first; it works. Only took somewhat 100seconds to generate.
